重构版本 v0.3.0 发布。
README:
介绍
本项目为Project Nichijou中的子项目,是Bangumi 番组计划的爬虫,用于构建番剧数据库。完整内容详见: https://project-nichijou.github.io/docs
关于爬虫
本项目实现了如下Spider:
bangumi_anime_list: 爬取动画列表,/anime/browser/?sort=title&page=<page>bangumi_anime_api: 爬取API提供的番剧信息bangumi_anime_scrape: 爬取网页上的番剧信息/subject/<sid>- 所有属性列表 (HTML)
- 标签 (空格隔开)
- 种类 (TV, OVA, …)
因为主项目的性质,故主要精力集中在番剧上面,如果您有其他需要可以自行实现 (欢迎提交PR!)
环境
- MySQL 5.7.4 +
- Python 3.6 +
- Scrapy
- beautifulsoup4
- Ubuntu (WSL)
- click (optional, 用于构建CLI)
- mysql-connector-python
- dill
配置方法
common子项目的配置,详见这里bangumi/config/bangumi_settings中配置本项目的相关字段bangumi(默认情况下无需更改)bangumi/config/scrapy_settings中配置scrapy的相关字段 (默认情况下无需更改)
关于Cookies
cookies.json中的cookies在某些情况下需要以下字段 (已经写在template当中了),否则无法爬取特殊内容,但是我们仍然建议把整个cookies都复制进来:
{
"chii_auth": <value>,
"chii_sec_id": <value>,
"chii_sid": <value>
}
注意:chii_sid由于会被Bangumi定期替换,所以我们手动实现了cookies变更持久化。当然,即便这样我们在爬取的时候还是有可能失效,毕竟我们只能停留在对机制的猜测阶段。是否开启cookies持久化可以在bangumi/config/bangumi_settings.py中的COOKIES_AUTO_UPDATE当中设置。如果开启,建议复制一份cookies.json保存为cookies.json.backup,因为文件会被复写,备份以便不时之需。
注意 (怎么又来了):关于cookies.json的格式:支持list和dict的两种格式。
上面的是dict,下面的是list举例:
[
{
"domain": ".bgm.tv",
"expirationDate": 1627660426.06073,
"hostOnly": false,
"httpOnly": false,
"name": "chii_auth",
"path": "/",
"sameSite": "unspecified",
"secure": false,
"session": false,
"storeId": "0",
"value": "<value>",
"id": 1
},
// 略...
]
推荐使用list配置cookies.json,不容易抽风。方法:可以使用类似于EditThisCookie的插件进行导出,见下图。
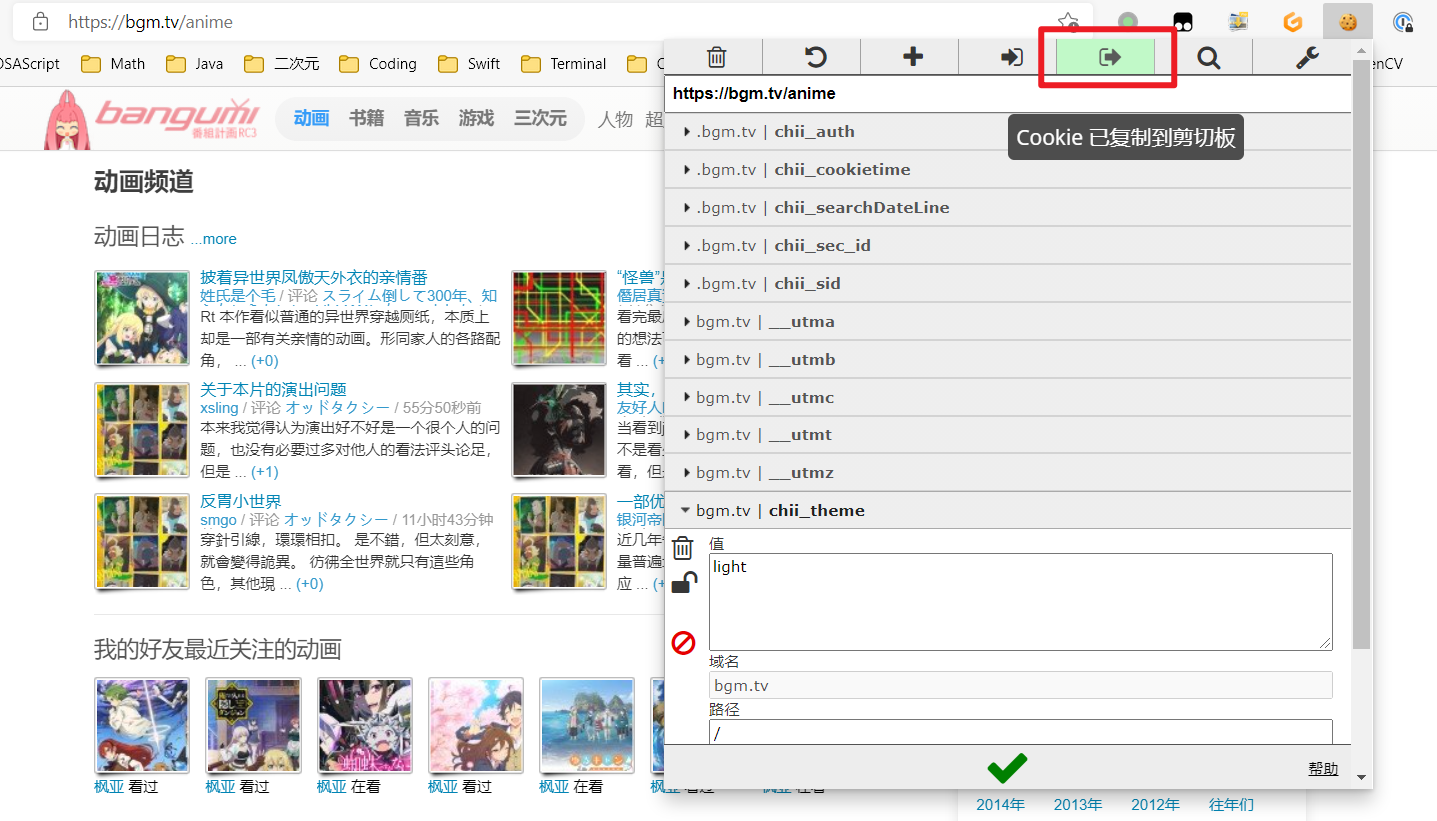
使用方法
经过考量,不准备使用scrapyd或者写启动服务器之类的功能,这里只提供了可以用于定时执行的脚本以及main.py的CLI工具。我们计划在以后统一实现后端整个工作流的控制管理,不在这里单一实现。目前,可以直接通过以下命令启动爬虫:
scrapy crawl <spider_name>
<spider_name>即为蜘蛛的文件名,位于bangumi/spider/目录下。
注意:对于部分蜘蛛,如bangumi_anime,有额外的参数。如果需要传参,请使用如下命令:
scarpy crawl <spider_name> -a <arg1>=<val1> <arg2>=<val2> ...
比如:
scrapy crawl bangumi_anime -a fail=off
或者也可以使用CLI命令:
- 主命令
python3 main.py Usage: main.py [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: crawl start SPIDER crawling using scrapy dellog delete loggings in the database. initdb init bangumi database setcookies set cookies of bangumi crawlpython3 main.py crawl --help Usage: main.py crawl [OPTIONS] SPIDER start SPIDER crawling using scrapy SPIDER: name of the spider to start Options: --fail INTEGER time of retrying for failed items. default is 0, when the value is negative, retrying won't stop unless the table `request_failed` is empty. Note: this parameter is not available for all spiders, only for `bangumi_anime_api`, `bangumi_anime_scrape`. --help Show this message and exit.dellogpython3 main.py dellog --help Usage: main.py dellog [OPTIONS] delete loggings in the database. Options: --before TEXT delete the loggings which are before the time in the database. default is None, which means delete all. data format: YYYY-MM-DD hh:mm:ss --help Show this message and exit.setcookiespython3 main.py setcookies --help Usage: main.py setcookies [OPTIONS] COOKIES set cookies of bangumi COOKIES: dictionary of cookies (converted to str) Options: --help Show this message and exit.
关于脚本
可以发现,在仓库的根目录我们还提供了下面的脚本:
run.sh
之所以提供脚本其实是因为scrapy没有提供定位到特定目录开始任务的命令行参数选项…所以我们就手动实现一下咯。
此脚本自动按顺序启动下面三个蜘蛛:
bangumi_anime_listbangumi_anime_scrapebangumi_anime_api
失败重试的次数设置为了两次,可以自行调整。
一些其他奇奇怪怪的点
- Bangumi自身数据有很大的可能性出问题,包括但不限于
- 本项目中,
parse出的所有结果一律使用yield, 不得使用return, 否则可能会出现无法进入pipelines的情况。原因不明,但是本项目中发生过这样有一个很典型的例子

